Today we're launching the Rankly Agent Directory, a free public catalog of every AI bot, crawler, and agent that touches the web. 4,171 unique entries, 308 operator roll-up pages, filterable by type and vendor, with a per-bot page that tells you what the bot does, how to identify it, whether to allow or block it, and what its traffic looks like in the wild. No signup. No paywall. Open it, search it, share it.
Why Bot Traffic Is Opaque
If you run a website in 2026, between a fifth and a third of your inbound requests are not humans. They're crawlers, fetchers, and increasingly, agents acting on behalf of someone using an AI product. Some of that traffic helps you (search indexers, link unfurlers, AI answer engines that cite back). Some of it costs you (training scrapers that consume bandwidth and send nothing back). Most of it is hard to tell apart at a glance.
The information you need to make a sensible allow/block decision is technically public, but it's scattered. Each vendor publishes its own bot docs in its own format, sometimes deep inside a privacy center, sometimes only in a community thread. IP-range JSON files are hosted under inconsistent paths. User-agent strings get revised quietly. Industry studies measure six bots and leave the other 4,000 to your imagination. By the time you've assembled enough context to make a call on a single user-agent in your logs, the bot population has shifted and you have to start over.
The directory exists to collapse that work. One page per bot, one page per operator, one consistent format. The taxonomy in our sidebar filter is the same taxonomy used on each bot page, so you don't have to translate between two parallel vocabularies. If a bot's vendor publishes IP ranges, we link them. If it doesn't, we say so. If the rate at which it gets blocked is in a published study, we cite the study. If it isn't, we mark the figure as an estimate.
What's In The Directory
Three page types, all linked together.
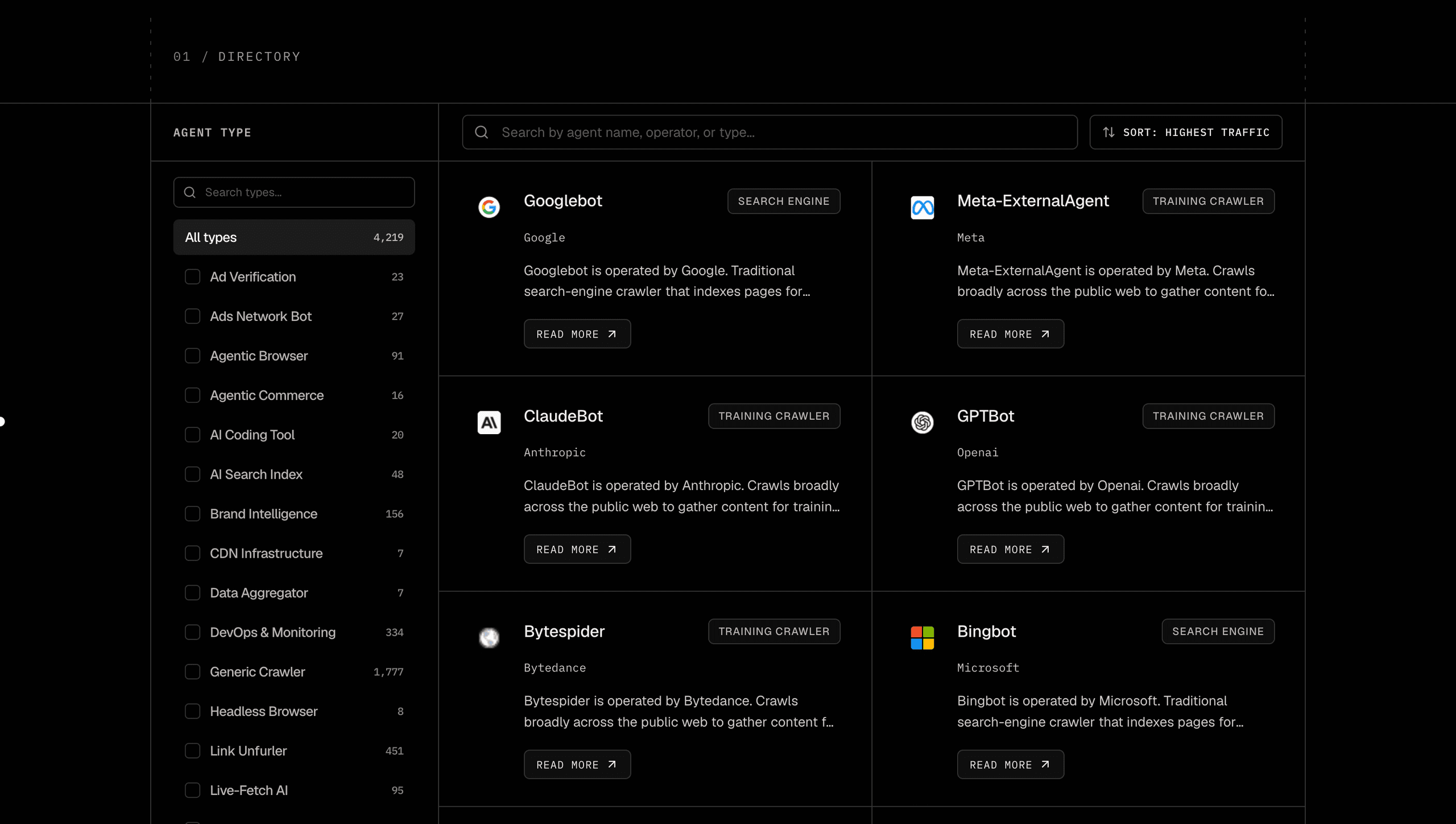
The listing
/agent-directory shows the full catalog in a two-column grid. The sidebar filters by agent type (Live-Fetch AI, Training Crawler, Agentic Browser, Search Engine, and the rest) and by operator (OpenAI, Anthropic, Google, Meta, ByteDance, and ~1,300 more). Both filter sections have their own search input so you can find a bot in seconds. Selections persist in the URL, so when you click into a detail page and hit back, the filter state is exactly where you left it. Default sort is by share of AI bot traffic, so the bots that actually move the needle for most sites surface first.
The detail pages
4,171 of them, one per unique bot slug. Each one tells you what the bot does, who operates it, the recommendation (allow / allow-with-rate-limit / investigate / block-or-monetize), the User-Agent strings to match against, the IP ranges to verify against (when published), the robots.txt rule that controls it, what traffic and blocking trends look like, a Rankly-voice FAQ tuned for the bot's type and family, and references back to the vendor's own docs.
The operator pages
308 of them, one per vendor that runs at least two bots. Useful for the OpenAI / Google / Anthropic / Apple / Meta question, "wait, how many bots does this company actually operate, and what does each one do?". The operator page is a single table with every bot for that vendor, its type, its purpose, and a one-line description. Click any row to land on its detail page.
Every entry is sourced from the operator's own documentation. OpenAI's bot docs, Anthropic's crawler page, Google Search Central, Apple's Applebot reference, Perplexity's bot guide, and the equivalent published page for every other vendor in the directory. Where a vendor publishes IP-range JSON, we link the live URL. Where a User-Agent string evolves (OpenAI cycles their Chrome version, for example), the page reflects the most recent published version. On top of that, Rankly adds entries for new agentic browsers, AI coding agents, AI shopping crawlers, and emerging operators we see in real traffic before they land in the public lists. Case-insensitive deduplication merges historical aliases (Bingbot/bingbot, Claude/Claude-Web/anthropic-ai), so you get one canonical page per real bot.
Anatomy Of An Agent Page
Take ChatGPT-User, OpenAI's live-fetch agent that pulls a page when a ChatGPT user is asking the model a question that needs current information. The page is laid out so a reader can answer four progressively-deeper questions without scrolling past noise.
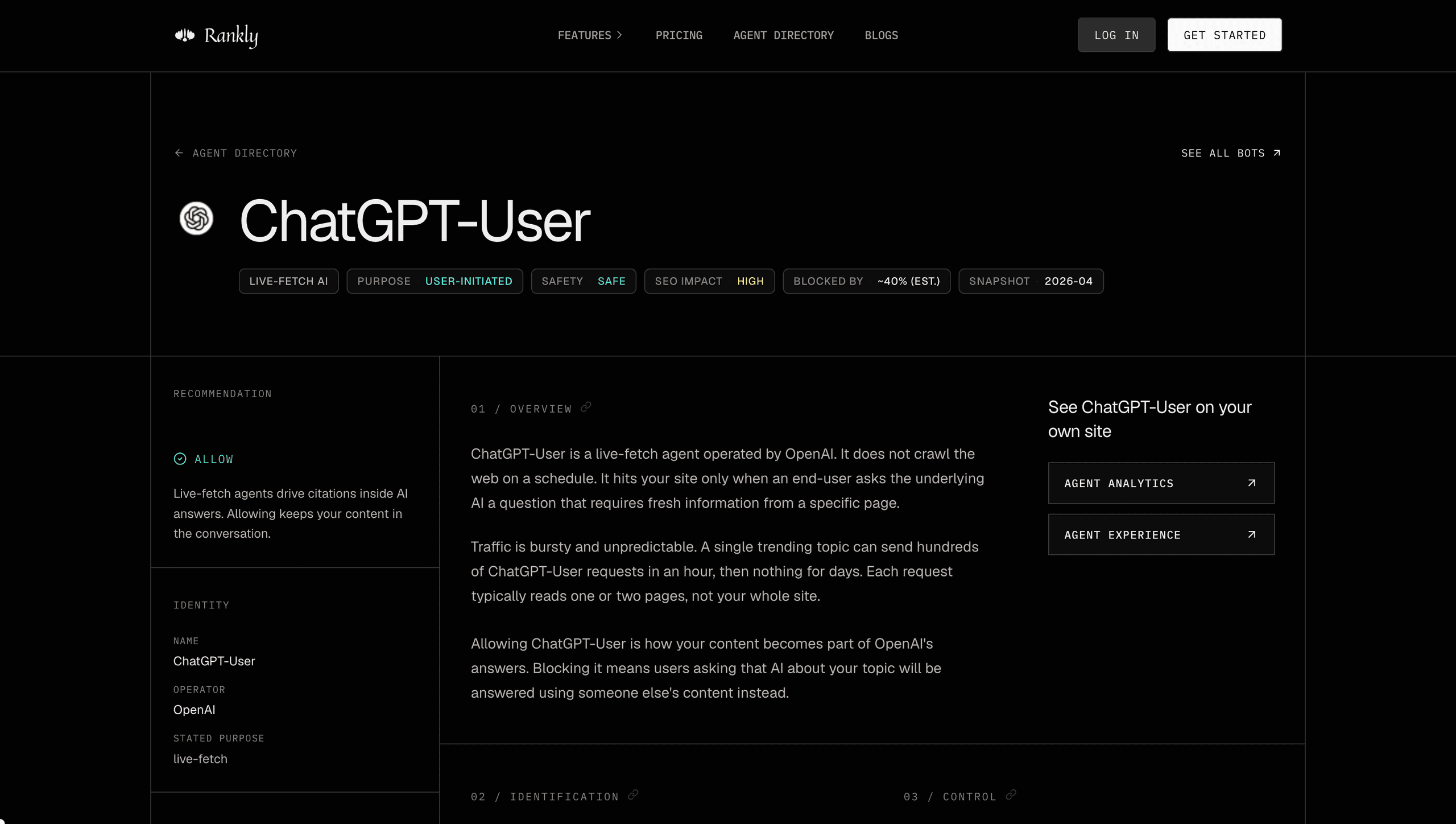
What is this thing?
Hero chips: type (Live-Fetch AI), purpose, safety class, SEO impact, block rate (when measured), and a snapshot date. Sidebar shows the operator (OpenAI), the recommendation (allow), and links to the rest of OpenAI's bot family.
How do I confirm it's really hitting my site?
Identification section: regex pattern for the User-Agent, the real UA strings OpenAI publishes (full, not truncated), and the IP-range JSON. We're explicit that User-Agent alone is spoofable, and that the IP-range check is the one that gives you confidence.
If I want to control it, what do I do?
Control section: the exact robots.txt rule. Plus a live URL tester where you paste your own site and we attempt a cross-origin robots.txt fetch and report Allow / Block / CORS-blocked. Your last-tested URL persists in your browser, so when you move between bot pages you don't retype it.
What does its traffic actually look like?
Traffic snapshot: trend lines for share of AI bot traffic, blocking rate, crawled categories, and geographic origin. Plus a KPI for crawl-to-click ratio. Every chart cites its source inline.
Underneath that, a common-questions section answers the things every site owner asks the first time they see a new bot in their logs: does blocking it hurt my Google rankings, what happens if I let it through, how is it different from the operator's other bots, what's the cleanest way to control it. Each section has an anchor link icon so you can share a deep link to a single answer.
Honesty About The Data
We took a hard look at every number on the site before launch. Industry studies tend to publish data for six or seven bots and leave readers to extrapolate to the rest. The result is that you end up citing a credible source for a figure the source never actually measured. We chose to mark that distinction clearly.
Block rates from BuzzStream's 2026 publishers-block-AI study are surfaced as a clickable citation only on the six bots BuzzStream actually measured (GPTBot, ClaudeBot, CCBot, PerplexityBot, Applebot-Extended, Google-Extended). Every other bot displays the same kind of figure prefixed with a tilde and an "estimated" tooltip that explains it's interpolated from macro trends, not a measured value. Crawl-to-click ratios come straight from Cloudflare's Aug 2025 industry blog: ClaudeBot at 38,066:1, GPTBot at 1,091:1, PerplexityBot at 195:1, Bingbot at ~41:1.
Monthly request volumes draw from Vercel's Dec 2024 'Rise of the AI crawler', which is the most cited dataset for cross-vendor comparison but is now five months old. We label it as a December 2024 snapshot rather than presenting it as a current-month measurement. For continuously-updating data we link out to Cloudflare Radar AI Insights from every operator page, because Cloudflare hosts that data live and nobody else needs to copy it.
Vendor docs, IP-range JSONs, and User-Agent strings come directly from the operators themselves. Where a string changes (OpenAI cycled the OAI-SearchBot Chrome version recently, for example), the directory tracks the most recent published version. Where a vendor doesn't publish a stable URL (Reddit, LinkedIn don't maintain dedicated bot-doc pages), we link to the closest authoritative source rather than fabricate one.
We'd rather show you a smaller verified number than a larger fake one.
What's Next
The directory is the read-only half of what Rankly is building. The two products coming next take it from a reference document into an operational stack:
Agent Analytics
Measure AI and human traffic side by side on your domain. See which agents visit, what they read, how often they come back, and how much referral traffic each one actually sends. Stop guessing whether ChatGPT-User is helping or just costing you bandwidth.
Agent Experience
Write rules at the edge that decide what AI agents and crawlers see. Allow, block, rate-limit, or serve a stripped-down HTML version per bot. Reduce cost, improve citation quality, and stay in control while humans still get the full page.
Together they close the loop: the directory tells you what each bot is, Agent Analytics tells you what each bot is doing on your domain specifically, Agent Experience lets you act on it.
In the meantime, the directory keeps growing. New agentic browsers, new AI shopping crawlers, new vendor families ship every week, and we add them as they show up in real traffic. If there's a bot you can't find or a piece of context you wish was on a page, send a note. The directory is the most useful when site owners help shape it.
